FFM-Llama2-v2
The world's first enhanced Traditional Chinese version of the FFM-Llama 2 (70B / 13B / 7B) series models, based on the latest generation native Meta Llama 2 large-scale language model, utilizes AIHPC supercomputer computing power, an optimized and efficient parallel computing environment, large language model segmentation technology, and a large amount of Traditional Chinese corpus for optimized training. v2 adds an expanded Traditional Chinese vocabulary, improving Traditional Chinese performance and inference efficiency.
FFM-Llama2-v2
★ World's first to feature Llama 2 language models with enhanced Traditional Chinese support ★
★ Offers FFM large language model options: 70B / 13B / 7B ★
★ Users can customize system role prompts for more accurate information responses ★
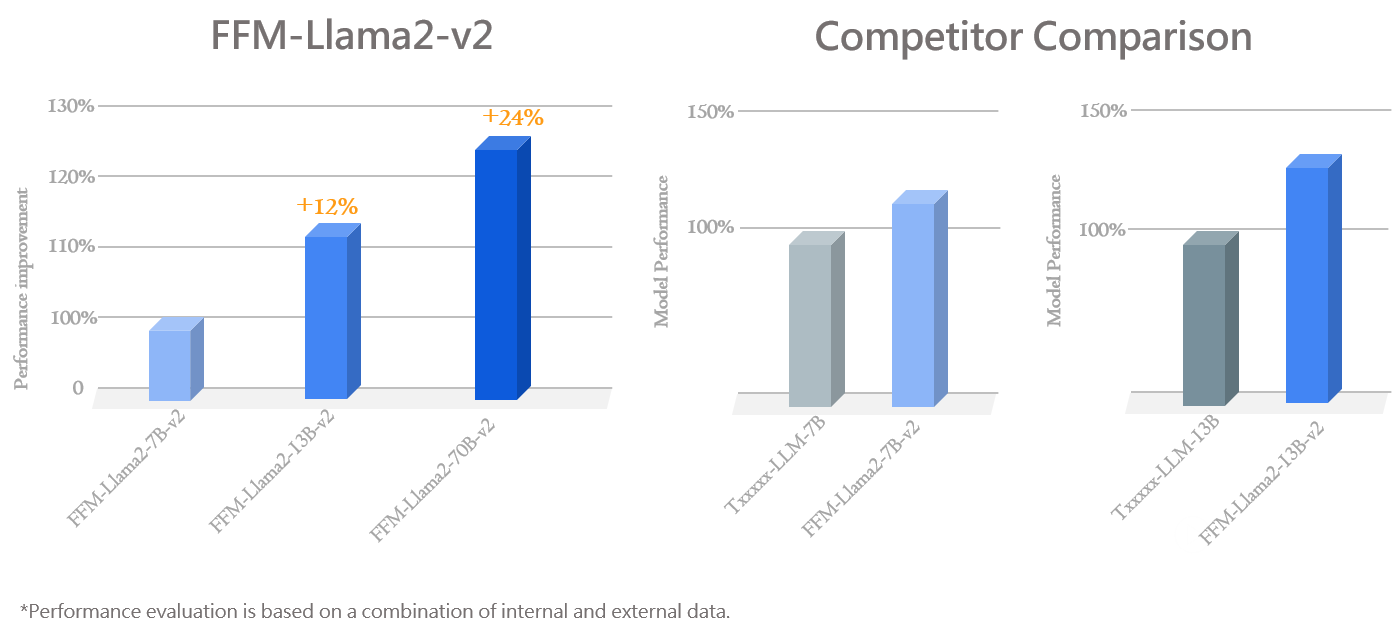
★ Continuously updated FFM-Llama2-v2, adding and expanding the vocabulary, significantly improving Traditional Chinese performance ★
★ FFM-Llama2-v2 reduces Traditional Chinese token usage by 50%, doubling model inference efficiency ★
Applicable Scenarios
Significantly improves Traditional Chinese capabilities, while retaining the excellent response methods and capabilities of native Meta Llama 2.
70B: Excellent understanding and reasoning skills in structured data, tables, and Markdown; ability to join data tables and use SQL and JSON; and proficiency in various application scenarios of 13B and 7B.
13B: Suitable for Markdown intent analysis + JSON format output, and various applicable scenarios of 7B.
7B: Can be used for marketing slogans and content generation, invitation and email writing, Chinese-English translation, article summarization, de-identification, and chatbot Q&A.
Parameter adjustment
Standard
Full parameter fine-tuning involves fine-tuning all parameters of a pre-trained model using a task-specific dataset, which requires significant GPU computing and storage resources.
PEFT
Parameter-Efficient Fine-Tuning fixes most of the pre-trained parameters and fine-tunes only a small number of additional model parameters, reducing computational and storage costs while approaching the effect of full parameter fine-tuning (LoRA is an applicable method).
LoRA (Low-Rank Adaptation of Large Language Models) fixes the pre-trained model parameters and weights, and adds additional network layer modules. By using a high-dimensional to low-dimensional decomposition matrix module, it updates only the parameters of the network layer modules to simulate the process of full parameter fine-tuning. This significantly reduces the number of parameters required for training, reduces computational and storage resources, and achieves indirect training of large models with fewer parameters, while approaching the effect of full model fine-tuning.