FFM-Embedding-v2
FFM-Embedding is a vector embedding model that enhances semantic search. It supports Traditional Chinese and eight other languages. v2 has been fully upgraded in terms of text length and vector dimensions, making information retrieval faster and semantically more accurate. v2.1 strengthens legal texts and enhances the recognition of legal terms and context.
FFM-Embedding-v2
★ A text vectorization tool that converts complex text data into vectors. ★
★ Used for information retrieval, RAG (Rapid Augmentation) vector construction and searching ★
★ Focuses on Traditional Chinese vector graphics and supports 8 other languages (English/German/French/Italian/Portuguese/Hindu/Spanish/Thai) ★
★ Significantly upgraded to 8K text length, improving search efficiency and enabling rapid processing of large amounts of information★
★ Customizable vector dimensions, up to 2048, flexibly adjustable for more accurate semantic search ★
★ OpenAI compatible; use OpenAI's Embedding API for quick model switching. ★
★ New v2.1: Enhanced legal texts, improved recognition of Traditional Chinese legal terminology and context ★
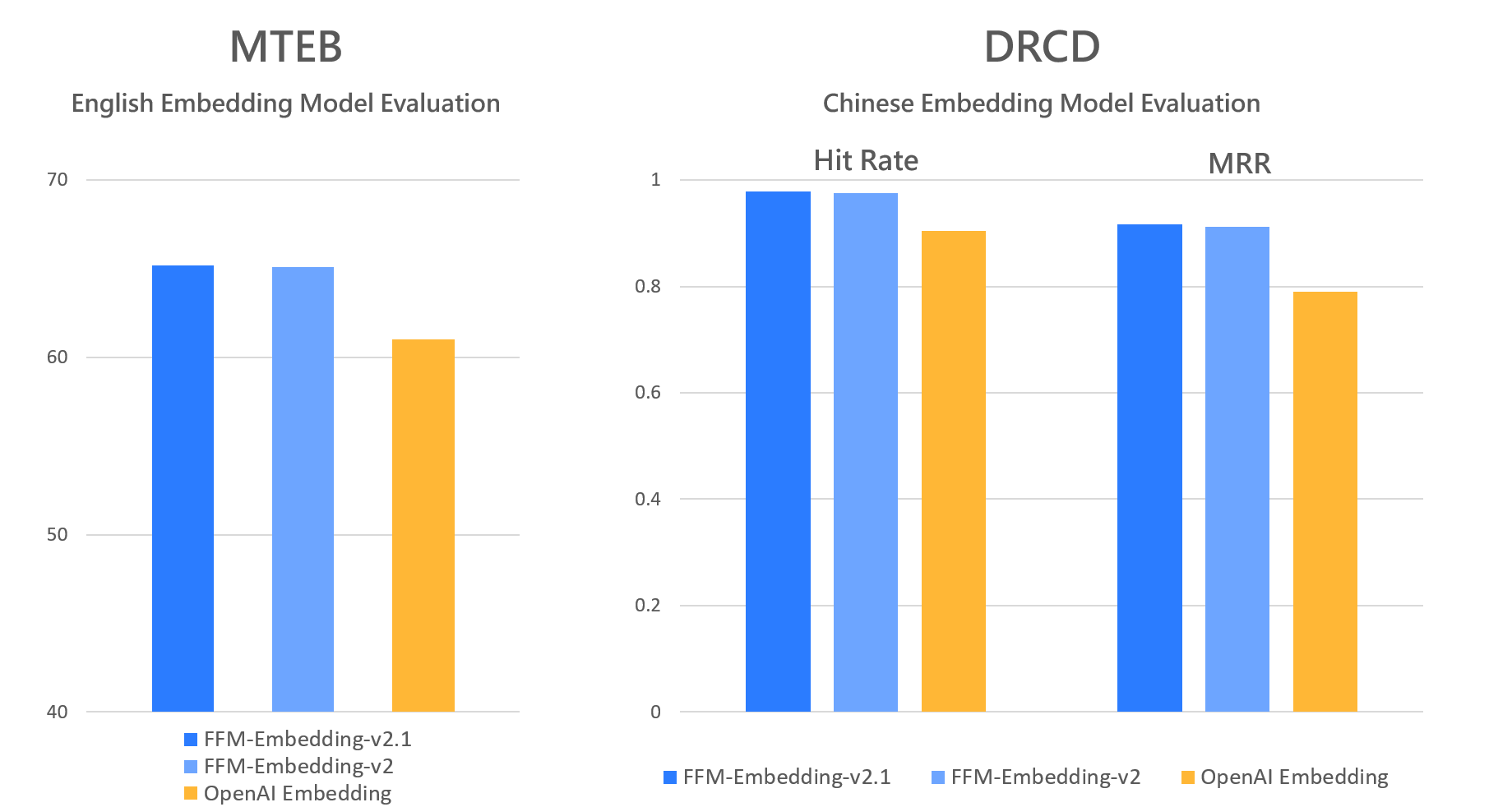
The benchmark surpasses OpenAI's best Traditional Chinese vector model.