Highly Secure and Deployable Enterprise-grade Generative AI Solutions.
Asia's only commercial AI supercomputing service and Taiwan's first enterprise-grade large-scale language model
AI 2.0 Era

Generative AI Brings New Value to Businesses – Productivity, Creativity, Efficiency, Cost Reduction
Latest Media Highlights
Generative AI Tailored Specifically for Enterprises
TWS, the only provider of commercial AI supercomputing services in Asia, has unveiled the first large-scale enterprise-level language model in Traditional Chinese called "Formosa Foundation Model." This model, built on Taiwan's Taiwania-2 supercomputer, comprises an impressive 176 billion parameters. It combines semantic understanding and text generation capabilities in Traditional Chinese, offering enterprise-grade, highly secure, and deployable generative AI solutions.

Generative AI is driving a productivity revolution, and the era of Moore’s Law for artificial intelligence systems has arrived. Enterprises can leverage the “Formosa Foundation Model,” a pre-trained model with general knowledge, to enhance their expertise using enterprise data. By deploying dedicated models in a trusted environment, businesses can establish their own tailored AI solutions and create an enterprise-specific brain.
AFS provides a customized advantage by utilizing dedicated models that align with the enterprise’s culture and specific needs. It offers unique practicality while ensuring compliance with enterprise security, regulations, and privacy. With AFS, sensitive data remains within the system, so you can safely and seamlessly integrate with internal enterprise systems without any worries.
Enterprise Benefits
Significantly reduce time cost, technical cost, development risk, hardware equipment, and manpower cost,
saving at least millions of USD in expenses

Reduce time cost
Reduce trial-and-error time and provide AI project consultants to assist the implementation of LLM (Large Language Model) in commercial applications

Reduce technical costs
Lead customers into the world of LLM with zero technical barriers and zero startup costs

Reduce development risk
Based on the proven success utilizing TWCC, fine-tune or train downstream tasks within the enterprise and transition smoothly from Proof of Concept (POC) to Proof of Business (POB) in one step.

Reduce investment cost
From Day 1, eliminate the investment cost of AIHPC hardware equipment, as well as the long-term manpower cost of AI technology investment and the need to replace outdated on-premises GPU Capex equipment

Exclusive model
Based on FFM (Formosa Foundation Model), assist in developing an 'industry-specific', efficient, and intelligent conversational AI system

Support multiple tasks
Capable of performing multiple tasks, including translation, programming, and text generation, and more.

No-code operation
No programming or LLM technical foundation required. With AFS service, you can access domain-specific LLM models and deployment services effortlessly

Auditable
Meets all requirements for enterprise security, SLA (Service Level Agreement), operational services, and compliance, without collecting or retaining any customer data and records during the process.
AFS (AI Foundry Service)
TWS combines AIHPC computing power with a No-code large model optimization platform to deliver a comprehensive enterprise-grade generative AI solution. The AFS series of services provide rapid access to AI supercomputing capabilities, easy model optimization, and flexible model deployment. TWS provides optimized AI models that are reliable, energy-efficient, and easily deployable, allowing enterprises to seamlessly migrate or adjust AI workloads between public and private clouds. With low software engineering thresholds and costs, the investment returns are several tens of times higher compared to renting cloud services and several thousand times higher compared to building AIHPC systems. This enables businesses to swiftly embrace the AI 2.0 application trend and implement it effectively.
AFS (AI Foundry Service) Pipeline:One-Stop Solution

Enterprise-level large model optimization solution
AFS Platform
Large language model optimization service
High-speed, secure, and convenient No-code large model optimization platform, billed on a pay-as-you-go basis per hour

Product Features
✓ Easy-to-use No-code Portal
✓ Multiple pre-trained models to choose from
✓ Convenient access to AIHPC supercomputer computing power
✓ National-level cybersecurity protection and tenant environment isolation
✓ Integration with secure network environments (including VPN) for enhanced security
✓ Low entry barrier, multiple computing power options, billed by the hour
Enterprise-level large model optimization solution
AFS Shuttle
Large language model optimization sharing services
Low cost and fast investment, the best choice for Proof of Concept (POC)

Product Features
✓ Easy-to-use No-code Portal
✓ Multiple pre-trained models to choose from
✓ Customizing the process based on customer requirements and the total number of readable tokens
✓ National-level cybersecurity protection and tenant environment isolation
✓ Integration with secure network environments (including VPN) for enhanced security
✓ Offering bundled fixed pricing to enterprise users for quick access to GPU resources for POC (Proof of Concept) validation
Enterprise-level large model deployment solution
AFS Appliance
On-premises deployment solution for large language model
The only solution in the market that enables direct deployment of enterprise-specific 176B large language model in on-premises data centers or private clouds.

Product Features
✓ The world’s first on-premises solution for large language model:Combining ASUS on-premises servers with TWS “Formosa Foundation Model”, this hardware-plus-software internal private cloud deployment solution allows for the installation of complete operating systems, parallel computing software packages, model fine-tuning, inference API calls, and ensures the highest level of security and peace of mind.
✓ Data security and compliance, safeguarding sensitive and private data:Ideal for industries with high sensitivity and compliance requirements such as healthcare, finance, legal, manufacturing, and more.
✓ GPU Server:ASUS ESC-N8, ESC8000 series, and ESC4000 series GPU Servers provide optimized computing power. These servers have undergone rigorous testing and are equipped with ASUS’s exclusive performance tuning technology to deliver exceptional computing capabilities. ASUS GPU Servers are also NVIDIA enterprise-certified, can ensure full utilization of computational power and provide excellent AI computing experiences, especially in the application of generative AI.
✓ Complete on-premises solution:Combined with TWS generative AI software solution and 5G enterprise network, it can provide the first all-in-one generative AI solution. From hardware calibration to software deployment, it offers a comprehensive enterprise-grade service in a single machine.
Enterprise-level large model deployment solution
AFS Cloud
Large language model hosting service
Elastic deployment mode for cloud-based inference service

Product Features
✓ Effortlessly deploy on public cloud:With stable specifications, we assist customers in managing their proprietary large language models and utilizing inference services on TWCC public cloud. The configuration is easily set up through a user-friendly No-code Portal, so there’s no need to worry about model storage, deployment, and hardware infrastructure.
✓ Data security and compliance, safeguarding sensitive and private data:Ideal for industries with industries such as retail, e-commerce, SaaS, and other sectors that heavily rely on internet/cloud services.
✓ Rapid validation:The Playground/Chat service interface allows for quick interaction and validation with the fine-tuned model. The interface also provides options to adjust relevant parameters for rapid validation of results with different parameter settings.
✓ Flexible and versatile:TWS offers optimized AI models that are reliable, energy-efficient, and easily deployable. This allows businesses to seamlessly migrate or adjust their AI workloads between public and private clouds.
Formosa Foundation Model (FFM)
Taiwan's first enterprise-grade large-scale language model
The "Formosa Foundation Model" is trained based on the 768 GPU and the AIHPC supercomputer environment. The FFM large language model options (176B, 7B) provide Playground for enterprise testing. Its performance is at a level close to GPT3.5 but with updated data. It is enhanced with Taiwanese-specific language resources and knowledge, and also supports multiple languages.
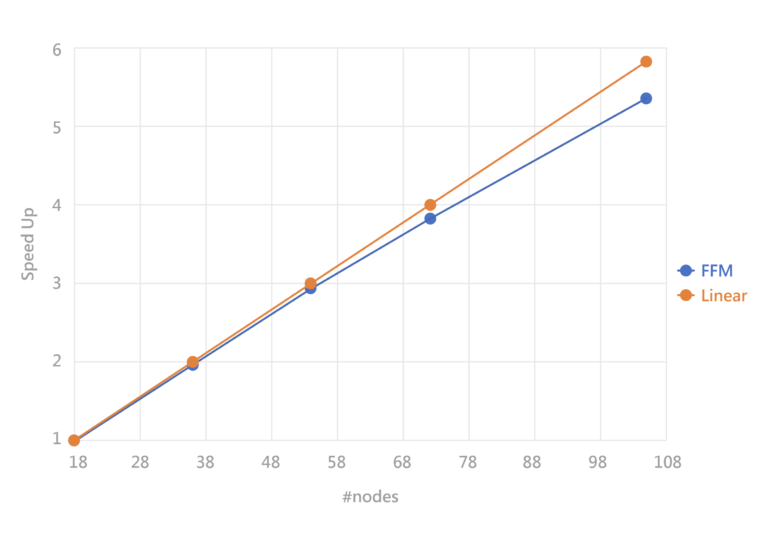
Successfully achieved linear acceleration results
Traditional cross-node parallel computing can experience performance degradation as the number of nodes increases. For example, if the computing power of one node is 100, according to linear theory, two nodes should have a combined computing power of 200. However, in practice, it might be reduced to 180 due to the decreased efficiency of inter-node communication and transmission.
In TWCC’s cross-node parallel computing environment, the InfiniBand architecture effectively facilitates collaborative operation among nodes. This implementation allows the execution of the Formosa Foundation Model to achieve near-linear performance, providing nearly perfect high-performance validation. It helps users fully leverage computational power and ensure that every investment is utilized optimally.
Fast, efficient, and low entry barrier.
Runnable large models
- BLOOM 176B requires precise model partitioning for distributed training
- TWS provides AIHPC cross-node supercomputer services
Run without burden
- Reasonable price / high CP value
- Capable of running multiple tests simultaneously to accelerate R&D process
- Option to choose larger-sized models
Run faster
- Cross-node GPU high-performance computing
- Infiniband 100G network
- IBM GPFS high-performance file system
- NVLink
Run better
- Professional service team
- Reduce migration cost
- Assist customers with BLOOM-related issues
FAQs
The innovative model of semiconductor foundries in Taiwan has driven the global IC design industry and the overall semiconductor and technology industry to thrive for several decades. TWS introduces AI Foundry Service to provide industrial services for computing power. It also offers opportunities for every enterprise to develop its own strengths based on the open computing resources provided by TWS and aims to establish an AI 2.0 industry ecosystem of co-creation and mutual prosperity. By launching new business models and services in the AI service industry, it is driving the transformation of Taiwan’s industries with AI.
TWS offers a one-stop AFS (AI Foundry Service) pipeline that includes the AFS Platform for large language model optimization services. It allows you to optimize and fine-tune your dedicated LLM (Large Language Model) based on your specific needs, with the flexibility to use computing resources based on a “Pay As You Go” model, or use the AFS Shuttle (Large Language Model Optimization Sharing Service), which provides cost-effective and customized model validation solutions for large language model optimization. After the training is complete, we will store the weights of the enterprise-level LLM model and the corresponding training data in a dedicated space for subsequent deployment services. For enterprise users concerned about data security, compliance, and privacy issues of AI 2.0 large language models, you can choose a suitable hybrid deployment approach based on your specific needs, including “AFS Cloud” (large language model hosting service) for inference through APIs in the TWCC cloud, or “AFS Appliance” (large language model on-premises deployment solution) for direct deployment of dedicated models in an on-premises environment.
It is expected to be officially launched and available in July 2023. You can already submit your requirements and prepare your company’s proprietary data and information. For further assistance, please contact us at sales@twsc.io, and our dedicated team will be happy to assist you
The AFS Platform is priced based on the actual usage of GPU computing resources by the enterprise. It can be calculated in terms of equivalent throughput (tokens/hr). The pricing is based on a pay-as-you-go model, billed hourly, and provides dedicated computing resources for tenants.
AFS Shuttle offers fixed pricing packages for enterprise users to quickly access GPU resources for POC validation.
AFS Appliance offers on-premises private cloud deployment services and provides special project pricing for enterprises.
AFS Cloud large language model hosting service offers pay-as-you-go pricing based on hourly usage to facilitate enterprises to estimate operational costs and reduce the expenses of inference services.
If you have model optimization needs, you can refer to the following scenarios for selection:
Scenario 1: For quick and low-entry POC validation for enterprises, you can choose AFS Shuttle.
Scenario 2: For enterprises that require model training based on actual task needs and want to pay based on actual computational resource usage (Pay As You Go), you can subscribe to AFS Platform immediately.
If you have model deployment and inference needs, you can refer to the following scenarios for selection:
Scenario 3: For customers with sensitive data and security considerations, you can choose TWCC AFS Appliance, which allows you to deploy the enterprise’s fine-tuned large language models on-premises.
Scenario 4: For customers with cloud-based needs, you can choose AFS Cloud to perform model inference services through cloud hosting. You will be billed based on the GPU-hours used.
TWS’s AFS series provides enterprise users with dedicated “enterprise-level” generative AI solutions that meet the requirements of data security, SLA, operational services, and compliance according to specific needs. AFS also provides complete one-stop services, including POC validation for enterprise users, customized model optimization (fine-tuning), and deployment and inference of models in hybrid mode, both on-premises and in the cloud. Users can choose the appropriate service based on their specific needs. Please rest assured that TWCC will not retain any customer data or records from the use of AFS services or any interaction with other products, nor will such data be used as FFM training data.
The entire range of AFS services is built in compliance with national cybersecurity regulations. Your service and data are hosted in non-governmental A-grade computing facilities and enjoy the highest level of information security. For even higher sensitivity requirements, you can choose to deploy dedicated models on-premises using “AFS Appliance”
(On-premises deployment solution for large language models) provided by TWS. This ensures that internal enterprise data remains within the premises and eliminates the risk of data leakage.
FFM is a model developed by TWS based on the Large Language Model (LLM) technology, with an impressive parameter count of up to 176 billion. The original version of the model is BLOOMZ open source, which allows for commercial licensing and usage. TWS’s in-house technology research and development team, based on years of experience in the NLP field, has enhanced the performance of the model by strengthening the LLM technique of the pre-trained model. It demonstrates relatively significant high-quality performance in the understanding of Traditional Chinese language semantics and knowledge domain. While specifically targeting the diverse application needs of Taiwanese enterprise users in various domains, FFM also demonstrates high-quality results in text content generation and has the capability that encompasses global knowledge and multiple languages.
Yes, it can support. LangChain simplifies the development of applications using large language models. By leveraging the customization capabilities provided by LangChain (refer to the following link: https://python.langchain.com/en/latest/modules/models/llms/examples/custom_llm.html), application developers can write custom LLM wrappers based on the documentation and specify the address for deploying the FFM large language model within the wrapper.
To make it easier for enterprise customers to experience and interact with the Formosa Foundation Model (FFM), TWS plans to offer a chat user interface for trial usage through an application process subject to review. For enterprise customers who have completed custom model optimization (fine-tuning), we also provide a Playground interface for customers to validate model inference. We also guarantee that we will not retain any customer data or records generated during the use of our AFS (AI Foundry Service) services, or during interactions with Chat or Playground. Additionally, we will not use this data for FFM training. For more information about our services, please contact sales@twsc.io or contact us
Free Consultation Service
Contact our experts in Taiwan Web Service to learn more and get started with the right solution for you.